Today on Health in 2 Point 00, Jess and I catch up on loads of news in health tech. In this episode, Jess asks me about Amazon Care, doing telehealth, house calls, urgent care, drug delivery for their employees—could it change health delivery? Also, Echo raises $20 million for their smart stethescope; Bayer leads a $40 million round for OneDrop’s blood glucose meter; GoodRx buys telehealth company HeyDoctor; Rock Health investing $10M in InsideRx, and an undisclosed amount to Arine; and Peloton IPO’s today and everyone’s looking at it as a healthcare company (but no, it’s not). We end on some gossip, so tune in. —Matthew Holt
The system is unstable. We are already seeing the precursor waves of massive and multiple disturbances to come. Disruption at key leverage points, new entrants, shifting public awareness and serious political competition cast omens and signs of a highly changed future.
So what’s the frequency? What are the smart bets for a strategic chief financial officer at a payer or provider facing such a bumpy ride? They are radically different from today’s dominant consensus strategies. In this five-part series, Joe Flower lays out the argument, the nature of the instability, and the best-bet strategies.
Providers:
Cost. Get serious control of your costs. Most providers I talk to are dismissive. “Yeah, yeah, you’ve been saying that for 10 years. We’re on it, believe me.” But I don’t believe them. Observation of the industry makes it clear that most healthcare providers have not gone after costs with nearly the ferocity of other industries. Some providers that I have worked with and interviewed over recent years have gotten their full cost of ownership down to a level where they can survive on Medicaid rates (that’s not a typo, I mean Medicaid) and build bigger, stronger systems at the same time. They have proven it can be done. But this is far from the industry norm. In the new competition, getting your costs seriously down is not the way to win. It’s just the price of admission. In the new competition, any entity that can deliver any particular service at a lower price will steal that business from you. You need to be that entity.
Overtreatment and waste. Do a deep and honest analysis of how much of your book of business is actually not effective, not necessary, does not deliver value or satisfaction to the customer—because that book of business is likely to wither away under alternative financing arrangements. Keep in mind that among various studies, the low estimate of how much of healthcare delivers no real value to the customer (an estimate by doctors about their own specialties) is 20%. The high end (in a PricewaterhouseCoopers study) is 54.5%. Most studies and estimates cluster around 35%.
Abandon monopolistic practices. An “all system” fee-for-service contract hidden from public scrutiny is smart, but not wise. It may help this year, maybe next year, but in the longer run it creates vulnerability to political attack, legislation, and lawsuits, and also to shifts in the market. A semi-monopoly position allows you to charge a premium for your products, but it locks you into that ability to charge a premium. As the market shifts and finds ways around paying high prices, you will find that you will be forced to compete at the lower prices, but you will not have developed the partnerships, the strategies, and the product lines to do that. If there is no competition in your area, then compete with yourself to forestall lower-cost competition developing.
Birth your competition. The growth area in the new healthcare competition will be: “How to cut into the hospital’s bottom line by keeping people out of the hospital.” The most competitive business models in healthcare will be in the business of cutting off hospitals’ revenue streams upstream. Get into this business model, even if you are a hospital. Especially if you are a hospital. Get into this business and get better at it than any potential competition. Create high-performance bundled programs with deeply managed costs well below the industry median. Get into contracts with large buyers for particular niches in which you give financial and quality performance guarantees. If you can’t guarantee that you can drop the cost and improve the quality, you will lose that business to someone else who can show that track record and give that guarantee.
Put yourself into all the business models that are disrupting you, such as outpatient clinics, community clinics, mobile vans, mini-hospitals, stand-alone emergency departments, onsite clinics, personalized management of complex cases, direct-pay primary care and others. Make these businesses able to compete for market share by unshackling them from hospital pricing and facilities fees.
Risky? Sure, but you do not want to end up being just the super-expensive job shop at the end of the line that every single customer and buyer is making every effort to avoid.
Success Strategies for Payer CFOs
Read the list of strategies that healthcare providers
have to go through to survive and serve their market. Think through all the
assets, connections, and information that you have, and ask yourself two
questions:
How can we help providers succeed at those strategies?
How can we foster competition against them in all those strategies?
Head toward TPA: Employers are frustrated and headed toward disintermediation. So be in the business of helping them realize the full potential of self-funded healthcare. Third-party administration (TPA) can help employers, unions, pension plans and other buying agents to reduce their costs and then push that savings directly toward increased value for their healthcare consumers.
Aggressively push all solutions that are not fee-for-service. Use your research expertise and bargaining power to bring bundled services, medical tourism, full capitation, mini-capitation, reference pricing, onsite and near-site direct-pay clinics, as well as the innovations mentioned above.
Ignore borders. In some domains, the best value for your
customers may be found in Mexico, Canada, Europe, the Caribbean, or even South
Asia. U.S. healthcare providers need to be in competition with these foreign
providers, and increasingly are. Help your customers find that value. They
are already seeking it on their own.
Guarantee the financial security of your customers. It does not help you if your customers feel like they are in an adversarial relationship with you, that you and the healthcare providers are lying in wait to catch them out and cost them vast sums. Today, most of your customers fear exactly that. If your customers know that you will defend them vigorously against surprise billing, balance billing, and hidden out-of-network costs, you have a superior product. Get aggressive in your negotiations with providers to get contracts that prevent them from using these egregious practices on your customers. Go to bat for your customers. Honor your contracts. Honor the promise of the happy, healthy faces on your billboards, not the “gotcha” traps in the fine print.
Fund population health and healthy communities, in cooperation with existing healthcare providers, but even in competition with them if necessary. If you put yourself in a position to do better financially if your covered population is healthier, then the opioid crisis, rampant diabetes, and other population health problems turn into huge opportunity spaces.
We can already see this happening in various emerging Medicaid programs that are becoming more responsive to the social determinants of health. In a number of states Medicaid Managed Care Organizations are required to build their plans not just on providing medical care, but by in one way or another offering help for housing, transportation, nutrition and access to healthy food, social contacts, a whole range of the things that we know make a huge difference to our health.
Work with the disruptive
new entrants. Bring your data analytics to the next level anduse those analytics, your customer base, and your financial power to
catalyze the disruption that is coming.
Are
there ways that payers and providers can work together in coopetition? That’s
the subject of Part 5.
A huge new CT brain dataset was released the other day, with the goal of training models to detect intracranial haemorrhage. So far, it looks pretty good, although I haven’t dug into it in detail yet (and the devil is often in the detail).
Of course, this lead to cynicism from the usual suspects as well.
And the conversation continued from there, with thoughts ranging from “but since there is a hold out test set, how can you overfit?” to “the proposed solutions are never intended to be applied directly” (the latter from a previous competition winner).
As the discussion progressed, I realised that while we “all know” that competition results are more than a bit dubious in a clinical sense, I’ve never really seen a compelling explanation for why this is so.
Hopefully that is what this post is, an explanation for why competitions are not really about building useful AI systems.
DISCLAIMER: I originally wrote this post expecting it to be read by my usual readers, who know my general positions on a range of issues. Instead, it was spread widely on Twitter and HackerNews, and it is pretty clear that I didn’t provide enough context for a number of statements made. I am going to write a follow-up to clarify several things, but as a quick response to several common criticisms:
I don’t think AlexNet is a better model than ResNet. That position would be ridiculous, particularly given all of my published work uses resnets and densenets, not AlexNets.
I think this miscommunication came from me not defining my terms: a “useful” model would be one that works for the task it was trained on. It isn’t a model architecture. If architectures are developed in the course of competitions that are broadly useful, then that is a good architecture, but the particular implementation submitted to the competition is not necessarily a useful model.
The stats in this post are wrong, but they are meant to be wrong in the right direction. They are intended for illustration of the concept of crowd-based overfitting, not accuracy. Better approaches would almost all require information that isn’t available in public leaderboards. I may update the stats at some point to make them more accurate, but they will never be perfect.
I was trying something new with this post – it was a response to a Twitter conversation, so I wanted to see if I could write it in one day to keep it contemporaneous. Given my usual process is spending several weeks and many rewrites per post, this was a risk. I think the post still serves its purpose, but I don’t personally think the risk paid off. If I had taken even another day or two, I suspect I would have picked up most of these issues before publication. Mea culpa.
Let’s have a battle
Nothing wrong with a little competition.*
So what is a competition in medical AI? Here are a few options:
getting teams to try to solve a clinical problem
getting teams to explore how problems might be solved and to try novel solutions
getting teams to build a model that performs the best on the competition test set
a waste of time
Now, I’m not so jaded that I jump to the last option (what is valuable to spend time on is a matter of opinion, and clinical utility is only one consideration. More on this at the end of the article).
But what about the first three options? Do these models work for the clinical task, and do they lead to broadly applicable solutions and novelty, or are they only good in the competition and not in the real world?
(Spoiler: I’m going to argue the latter).
Good models and bad models
Should we expect this competition to produce good models? Let’s see what one of the organisers says.
Cool. Totally agree. The lack of large, well-labeled datasets is the biggest major barrier to building useful clinical AI, so this dataset should help.
But saying that the dataset can be useful is not the same thing as saying the competition will produce good models.
So to define our terms, let’s say that a good model is a model that can detect brain haemorrhages on unseen data (cases that the model has no knowledge of).
So conversely, a bad model is one that doesn’t detect brain haemorrhages in unseen data.
These definitions will be non-controversial. Machine Learning 101. I’m sure the contest organisers agree with these definitions, and would prefer their participants to be producing good models rather than bad models. In fact, they have clearly set up the competition in a way designed to promote good models.
It just isn’t enough.
Epi vs ML, FIGHT!
If only academic arguments were this cute
ML101 (now personified) tells us that the way to control overfitting is to use a hold-out test set, which is data that has not been seen during model training. This simulates seeing new patients in a clinical setting.
ML101 also says that hold-out data is only good for one test. If you test multiple models, then even if you don’t cheat and leak test information into your development process, your best result is probably an outlier which was only better than your worst result by chance.
So competition organisers these days produce hold-out test sets, and only let each team run their model on the data once. Problem solved, says ML101. The winner only tested once, so there is no reason to think they are an outlier, they just have the best model.
Not so fast, buddy.
Let me introduce you to Epidemiology 101, who claims to have a magic coin.
Epi101 tells you to flip the coin 10 times. If you get 8 or more heads, that confirms the coin is magic (while the assertion is clearly nonsense, you play along since you know that 8/10 heads equates to a p-value of <0.05 for a fair coin, so it must be legit).
Unbeknownst to you, Epi101 does the same thing with 99 other people, all of whom think they are the only one testing the coin. What do you expect to happen?
If the coin is totally normal and not magic, around 5 people will find that the coin is special. Seems obvious, but think about this in the context of the individuals. Those 5 people all only ran a single test. According to them, they have statistically significant evidence they are holding a “magic” coin.
Now imagine you aren’t flipping coins. Imagine you are all running a model on a competition test set. Instead of wondering if your coin is magic, you instead are hoping that your model is the best one, about to earn you $25,000.
Of course, you can’t submit more than one model. That would be cheating. One of the models could perform well, the equivalent of getting 8 heads with a fair coin, just by chance.
Good thing there is a rule against it submitting multiple models, or any one of the other 99 participants and their 99 models could win, just by being lucky…
Multiple hypothesis testing
The effect we saw with Epi101’s coin applies to our competition, of course. Due to random chance, some percentage of models will outperform other ones, even if they are all just as good as each other. Maths doesn’t care if it was one team that tested 100 models, or 100 teams.
Even if certain models are better than others in a meaningful sense^, unless you truly believe that the winner is uniquely able to ML-wizard, you have to accept that at least some other participants would have achieved similar results, and thus the winner only won because they got lucky. The real “best performance” will be somewhere back in the pack, probably above average but below the winner^^.
Epi101 says this effect is called multiple hypothesis testing. In the case of a competition, you have a ton of hypotheses – that each participant was better than all others. For 100 participants, 100 hypotheses.
One of those hypotheses, taken in isolation, might show us there is a winner with statistical significance (p<0.05). But taken together, even if the winner has a calculated “winning” p-value of less than 0.05, that doesn’t mean we only have a 5% chance of making an unjustified decision. In fact, if this was coin flips (which is easier to calculate but not absurdly different), we would have a greater than 99% chance that one or more people would “win” and come up with 8 heads!
That is what an AI competition winner is; an individual who happens to get 8 heads while flipping fair coins.
Interestingly, while ML101 is very clear that running 100 models yourself and picking the best one will result in overfitting, they rarely discuss this “overfitting of the crowds”. Strange, when you consider that almost all ML research is done of heavily over-tested public datasets …
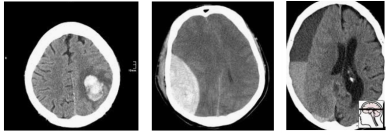
So how do we deal with multiple hypothesis testing? It all comes down to the cause of the problem, which is the data. Epi101 tells us that any test set is a biased version of the target population. In this case, the target population is “all patients with CT head imaging, with and without intracranial haemorrhage”. Let’s look at how this kind of bias might play out, with a toy example of a small hypothetical population:
In this population, we have a pretty reasonable “clinical” mix of cases. 3 intra-cerebral bleeds (likely related to high blood pressure or stroke), and two traumatic bleeds (a subdural on the right, and an extradural second from the left).
Now let’s sample this population to build our test set:
Randomly, we end up with mostly extra-axial (outside of the brain itself) bleeds. A model that performs well on this test will not necessarily work as well on real patients. In fact, you might expect a model that is really good at extra-axial bleeds at the expense of intra-cerebral bleeds to win.
But Epi101 doesn’t only point out problems. Epi101 has a solution.
So powerful
There is only one way to have an unbiased test set – if it includes the entire population! Then whatever model does well in the test will also be the best in practice, because you tested it on all possible future patients (which seems difficult).
This leads to a very simple idea – your test results become more reliable as the test set gets larger. We can actually predict how reliable test sets are using power calculations.
These are power curves. If you have a rough idea of how much better your “winning” model will be than the next best model, you can estimate how many test cases you need to reliably show that it is better.
So to find out if you model is 10% better than a competitor, you would need about 300 test cases. You can also see how exponentially the number of cases needed grows as the difference between models gets narrower.
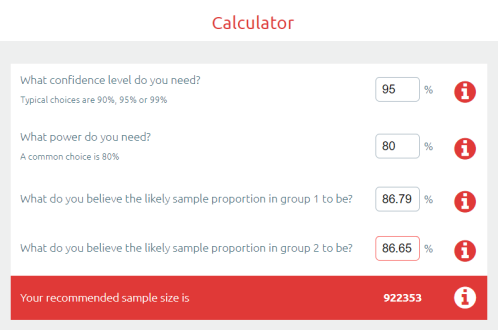
Let’s put this into practice. If we look at another medical AI competition, the SIIM-ACR pneumothorax segmentation challenge, we see that the difference in Dice scores (ranging between 0 and 1) is negligible at the top of the leaderboard. Keep in mind that this competition had a dataset of 3200 cases (and that is being generous, they don’t all contribute to the Dice score equally).
So the difference between the top two was 0.0014 … let’s chuck that into a sample size calculator.
Ok, so to show a significant difference between these two results, you would need 920,000 cases.
But why stop there? We haven’t even discussed multiple hypothesis testing yet. This absurd number of cases needed is simply if there was ever only one hypothesis, meaning only two participants.
If we look at the leaderboard, there were 351 teams who made submissions. The rules say they could submit two models, so we might as well assume there were at least 500 tests. This has to produce some outliers, just like 500 people flipping a fair coin.
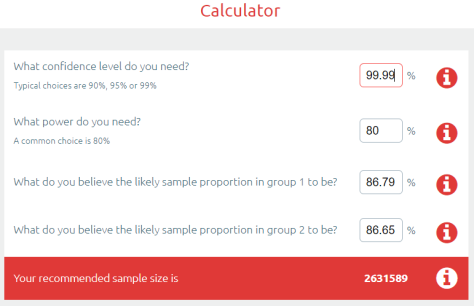
Epi101 to the rescue. Multiple hypothesis testing is really common in medicine, particularly in “big data” fields like genomics. We have spent the last few decades learning how to deal with this. The simplest reliable way to manage this problem is called the Bonferroni correction^^.
The Bonferroni correction is super simple: you divide the p-value by the number of tests to find a “statistical significance threshold” that has been adjusted for all those extra coin flips. So in this case, we do 0.05/500. Our new p-value target is 0.0001, any result worse than this will be considered to support the null hypothesis (that the competitors performed equally well on the test set). So let’s plug that in our power calculator.
Cool! It only increased a bit… to 2.6 million cases needed for a valid result :p
Now, you might say I am being very unfair here, and that there must be some small group of good models at the top of the leaderboard that are not clearly different from each other^^^. Fine, lets be generous. Surely no-one will complain if I compare the 1st place model to the 150th model?
So still more data than we had. In fact, I have to go down to the 192nd placeholder to find a result where the sample size was enough to produce a “statistically significant” difference.
But maybe this is specific to the pneumothorax challenge? What about other competitions?
In MURA, we have a test set of 207 x-rays, with 70 teams submitting “no more than two models per month”, so lets be generous and say 100 models were submitted. Running the numbers, the “first place” model is only significant versus the 56th placeholder and below.
In the RSNA Pneumonia Detection Challenge, there were 3000 test images with 350 teams submitting one model each. The first place was only significant compared to the 30th place and below.
And to really put the cat amongst the pigeons, what about outside of medicine?
As we go left to right in ImageNet results, the improvement year on year slows (the effect size decreases) and the number of people who have tested on the dataset increases. I can’t really estimate the numbers, but knowing what we know about multiple testing does anyone really believe the SOTA rush in the mid 2010s was anything but crowdsourced overfitting?
So what are competitions for?
They obviously aren’t to reliably find the best model. They don’t even really reveal useful techniques to build great models, because we don’t know which of the hundred plus models actually used a good, reliable method, and which method just happened to fit the under-powered test set.
You talk to competition organisers … and they mostly say that competitions are for publicity. And that is enough, I guess.
AI competitions are fun, community building, talent scouting, brand promoting, and attention grabbing.
But AI competitions are not to develop useful models.
* I have a young daughter, don’t judge me for my encyclopaedic knowledge of My Little Pony.**
** not that there is anything wrong with My Little Pony***. Friendship is magic. There is just an unsavoury internet element that matches my demographic who is really into the show. I’m no brony.
*** barring the near complete white-washing of a children’s show about multi-coloured horses.
^ we can actually understand model performance with our coin analogy. Improving the model would be equivalent to bending the coin. If you are good at coin bending, doing this will make it more likely to land on heads, but unless it is 100% likely you still have no guarantee to “win”. If you have a 60%-chance-of-heads coin, and everyone else has a 50% coin, you objectively have the best coin, but your chance of getting 8 heads out of 10 flips is still only 17%. Better than the 5% the rest of the field have, but remember that there are 99 of them. They have a cumulative chance of over 99% that one of them will get 8 or more heads.
^^ people often say the Bonferroni correction is a bit conservative, but remember, we are coming in skeptical that these models are actually different from each other. We should be conservative.
^^^ do please note, the top model here got $30,000 and the second model got nothing. The competition organisers felt that the distinction was reasonable.
Luke Oakden-Rayner is a radiologist (medical specialist) in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
When you ask the ‘big data guy’ at a massive health system what’s wrong with EMRs, it’s surprising to hear that his problem is NOT with the EMRs themselves but with the fact that health systems are just not using the data their collecting in any meaningful way. Atul Butte, Chief Data Scientist for University of California Health System says interoperability is not the big issue! Instead, he says it’s the fact that health systems are not using some of the most expensive data in the country (we are using doctors to data entry it…) to draw big, game-changing conclusions about the way we practice medicine and deliver care. Listen in to find out why Atul thinks that the business incentives are misaligned for a data revolution and what we need to do to help.
Filmed at Health Datapalooza in Washington DC, March 2019.
Jessica DaMassa is the host of the WTF Health show & stars in Health in 2 Point 00 with Matthew Holt.
Get a glimpse of the future of healthcare by meeting the people who are going to change it. Find more WTF Health interviews here or check out www.wtf.health.
The chest CT report was a bit worrisome. Henry had “pleural based masses” that had grown since his previous scan, which had been ordered by another doctor for unrelated reasons. But as Henry’s PCP, it had become my job to follow up on an emergency room doctor’s incidental finding. The radiologist recommended a PET scan to see if there was increased metabolic activity, which would mean the spots were likely cancerous.
So the head of radiology says this is needed. But I am the treating physician, so I have to put the order in. In my clunky EMR I search for an appropriate diagnostic code in situations like this. This software (Greenway) is not like Google; if you don’t search for exactly what the bureaucratic term is, but use clinical terms instead, it doesn’t suggest alternatives (unrelated everyday example – what a doctor calls a laceration is “open wound” in insurance speak but the computer doesn’t know they’re the same thing).
So here I am, trying to find the appropriate ICD-10 code to buy Henry a PET scan. Why can’t I find the diagnosis code I used to get the recent CT order in when I placed it, months ago? I cruise down the list of diagnoses in his EMR “chart”. There, I find every diagnosis that was ever entered. They are not listed alphabetically or chronologically. The list appears totally random, although perhaps the list is organized alphanumerically by ICD-10, although they are not not displayed in my search box, but that wouldn’t do me any good anyway since I don’t have more than five ICD-10 codes memorized.
Patients are waiting, I’m behind, the usual time pressure in healthcare.
Can’t find a previously used diagnosis. Search for “nonspecific finding on chest X-ray” and multiple variations thereof.
I see R93.89 – “abnormal finding on diagnostic imaging of other body structures”. Close enough, use it, type in exactly what the chief of radiology had said in his report. Move on. Next patient.
Several days later I get a printout of that order in my inbox with a memo that the diagnosis doesn’t justify payment for a PET scan. Attached to that is a multi page list of diagnoses that would work.
Frustrated, I go through the list. It’s another day, other patients are waiting. Eventually I come across R91.8 “other nonspecific finding of lung field” – not exactly pleura, but what the heck, close enough, let’s use that one.
Why is this – me hurriedly choosing the next best thing on a multipage printout, while my other patients are waiting – any more practical, accurate or fraud proof than having me describe in appropriate CLINICAL language what the patient needs and letting SOMEONE ELSE look for the darn code?
Here I am, trying to order what a radiologist told me to order, without having the tools to do it.
Next thing you know, Henry’s insurance will probably have some third party radiologist deny coverage because he disagrees with my radiologist, and I’ll be stuck in the middle…
Not quite what I thought I’d be doing. Who works for whom in healthcare?
Hans Duvefelt is a Swedish-born rural Family Physician in Maine. This post originally appeared on his blog, A Country Doctor Writes, here.
In the 2020 Summer Olympics, we will undoubtedly see large, red circles down the arms and backs of many Olympians. These spots are a side-effect of cupping, a treatment originating from traditional Chinese medicine (TCM) to reduce pain. TCM is a globally used Complementary and Alternative Medicine (CAM), but it still battles its critics who think it is only a belief system, rather than a legitimate medical practice. Even so, the usage of TCM continues to grow. This led the National Institute of Health (NIH) to sponsor a meeting in 1997 to determine the efficacy of acupuncture, paving the way in CAM research. Today, there are now over 50 schools dedicated to teaching Chinese acupuncture in the US under the Accreditation Commission for Acupuncture & Oriental Medicine.
Image of Michael Phelps swimming in 2016 Rio Olympics after using TCM cupping. (Al Bello/Getty Images)
While TCM has seen immense growth and integration around the globe throughout the last twenty years, other forms of CAM continue to struggle for acceptance in the U.S. In this article we will focus on Native American/Indigenous traditional medical practices. Indigenous and non-Indigenous patients should not have to choose between traditional and allopathic medicine, but rather have them working harmoniously from prevention to diagnosis to treatment plan.
It was not until August of 1978 that federally recognized tribal members were officially able to openly practice their Indigenous traditional medicine (the knowledge and practices of Indigenous people that prevent or eliminate physical, mental and social diseases) when the American Indian Religious Freedom Act (AIRFA) was passed. Prior to 1978, the federal government’s Department of Interior could convict a medicine man to a minimum of 10 days in prison if he encouraged others to follow traditional practices.
It is difficult to comprehend that tribes throughout the U.S. were only given the ability to openly exercise their medicinal practices 41 years ago when the “healing traditions of indigenous Native Americans have been practiced on this continent for 12,000 years ago and possibly for more than 40,000 years.”[1]
Since the passage of AIRFA, many tribally run clinics and hospitals are finding ways to incorporate Indigenous traditional healing into their treatment plans, when requested by patients.
Examples include the Puyallup Tribe of Indians’ Salish Cancer Center in Washington and the Southcentral Foundation, a nonprofit Native-owned healthcare organization in Alaska. At the Salish Cancer Center, Native healers are brought in from various tribes around the US twice a month, allowing patients to adhere to their own tribal protocol and healers to have direct communication with oncologists at the center.
In 2011, the Southcentral Foundation Traditional Healing Clinic received the Indian Health Service Director’s Special Recognition Award for “demonstrating how tribal doctors, elders, and traditional healing practices can work side-by-side with Western medicine… for the ultimate benefit of Native patients, families, and communities.”
While we may be wondering how effective bringing Native healers is for patient outcomes, these data are seldom shared. Traditional healing is a very sacred practice, and for both the patient and healer, many tribal members choose not to share information publicly.
So rather than attempt to figure out the efficacy of integrating Indigenous traditional healing and allopathic medicine, we share a story about when they worked together synergistically:
On the Navajo Reservation in 1952, there was a tuberculosis (TB) epidemic. The TB rate for the Navajo population was ten times the rate of occurrences in the Caucasian population in the same geographic region. 302/100,000 Navajos had TB compared to 30/100,000 Caucasians. Dr. Walsh McDermott, from Cornell Medical College, heard about this emergency of untreated TB and organized to bring a group comprised of doctors and researchers to the reservation from Cornell Medical College. This came to be known as the Many Farms Demonstration Project.
An image taken while Dr. McDermott was on the Navajo Nation Reservation during the Many Farms Demonstration Project.
Unlike the federal government, Dr. McDermott welcomed traditional healers and community leaders into his work and acquainted them with the procedures being used.
This relationship proved beneficial to ending the epidemic because the traditional healer was able to solve a problem that the Western-trained doctors could not. When lightning struck near the hospital, Dr. McDermott’s patients began to flee because of their traditional belief that lightening brings misfortune. A Navajo medicine man was brought in to bless both the hospital and patients, and to appease the spirits. The patients, trusting their medicine man’s healing of the land and space, subsequently came back in because they were confident that there was no more danger. This made it so their TB treatment could begin again.
From a Western science perspective, there may not be many randomized controlled trials to prove the efficacy of Indigenous traditional medicine. The example above, though, clearly shows that the use of Western science in isolation would not have produced the cures it had sought. For allopathic medicine to have its intended effects in improving health outcomes of populations who use CAM, it must work harmoniously with CAM and respect it. As the Indian Health Service lays out in its policy, the “respect and acceptance [of] an individual’s private traditional beliefs become a part of the healing and harmonizing force within his/her life.”
Internist, Pediatrician, and Associate Professor at UCSF, Dr. Le is also the co-founder of two health equity organizations, the HEAL Initiative and Arc Health.
Brooke Warren is a Native American Studies major and recent graduate of UC Davis. She is currently an intern at Arc Health.
Three finalists for the Robert Wood Johnson
Foundation Home and Community Based Care and Social Determinants of Health
Innovation Challenges competed live at the Health 2.0 Conference on Monday,
September 16th! They demoed their technology in front of a captivated audience
of health care professionals, investors, provider organizations, and members of
the media. Catalyst is proud to announce the first, second and third place
winners.
Home and Community Based Care Innovation Challenge Winners
For the SDoH Challenge, innovators
were asked to develop novel digital solutions that can help providers and/or
patients connect to health services related to SDoH. Over 110 applications were
submitted. For the Home and Community Based Care Challenge, applicants were
asked to create technologies that support the advancement of at-home or
community-based health care. Nearly 100 applications for Home and Community
Based Care Challenge were received. After the submission period ended, an
expert of over 50 judges evaluated the entries. Five semi-finalists from each
challenge were selected to advance to the next round and further develop their
solutions. The semi-finalists were evaluated again and the three finalists
chosen.
To learn more about the Home and Community Based Care Innovation Challenge, click here.
To learn more about the Social Determinants of Health Innovation Challenge, click here.
For further updates on the finalists of the RWJF SDoH and Home and Community Based Care Innovation Challenge and other programs, please subscribe to the Catalyst @ Health 2.0 Newsletter, and follow us on Twitter @catalyst_h20.
Catalyst @ Health 2.0 (“Catalyst”) is the industry leader in digital health strategic partnering, hosting competitive innovation “challenge” events and developing programs for piloting and commercializing novel healthcare technologies.
Digital therapeutics has exploded as the new hot buzzword in digital health. But how are digital therapeutics different from digital health applications, applied health signals, or m-health technologies? The Digital Therapeutics Alliance was formed to answer that exact question. DTA Executive Director Megan Coder sets the record straight, hint: it involves software algorithms.
Filmed at JP Morgan Healthcare in San Francisco, CA, January 2019.
Jessica DaMassa is the host of the WTF Health show & stars in Health in 2 Point 00 with Matthew Holt.
Get a glimpse of the future of healthcare by meeting the people who are going to change it. Find more WTF Health interviews here or check out www.wtf.health.
Picture, if you will, a healthcare sector that costs less, whose share of the national economy is more like it is in other advanced economies—let’s imagine 9% or 10% rather than 18% or 19%.
A big part of this drop is a vast reduction in overtreatment because non-fee-for-service payment systems are far less likely to pay for things that don’t help the patient. Another part of this drop is the greater efficiency of every procedure and process as providers get better at knowing their true costs and cutting out waste. The third major factor is that new payment systems and business models actually drive toward true value for the buyers and healthcare consumers. This includes giving a return on the investment for prevention, population health management, and building healthier communities. This incentive would reduce the large percentage of healthcare costs due to preventable and manageable diseases, trauma, and addictions.
Picture, if you
will, a healthcare sector in which prices are real, known, and reliable.
Price outliers that today may be two, three, five times the industry median
have rapidly disappeared. Prices for comparable procedures have normalized in a
narrower range well below today’s median prices. Most prices are bundled, a
single price for an entire procedure or process, in ways that can be compared
across the entire industry. Prices are guaranteed. There are no circumstances
under which a healthcare provider can decide after the fact how much to charge,
or a health insurer can decide after the fact that the procedure was not
covered, or that the unconscious heart attack victim should have been taken to
a different emergency department farther away.
Picture a
well-informed, savvy healthcare consumer, with active support and incentives
from their employers and payors, who is far more willing and eager to find out what their choices are and exercise that
choice. They want the same level of service, quality, and financial choices
they get from almost every other industry. And as their financial burden
increases, so do their demands.
Picture a reversing
of consolidation, ending a providers’ ability to demand full-network
contracting with opaque price agreements—and encouraging new market entrants
capable of facilitating a yeasty market for competition. Picture growing
disintermediation and decentralization of healthcare, with buyers increasingly
able to act like real customers, picking and choosing particular services based
on price and quality.
Picture an
industry whose processes are as revolutionized by new technologies
as the news industry has been, or gaming, or energy. Picture a healthcare
industry in which you simply cannot compete using yesterday’s technologies—not
just clinical technologies but data, communications, and transaction
technologies.
True Value
Other
industries define their “value proposition” as: How do we succeed by bringing
the customer greater real value, with products and services that have some
combination of lower price, greater reliability, and more functionality? The
question is: “How do we get the job done better at a reasonable price?”
That would be a
radical re-definition for healthcare. It is simply not what today’s
structures are built for. The fee-for-service model by its nature cannot drive
toward true value for the customer. Yet this radical re-definition is exactly
what all of healthcare’s customers and buyers and all of the new disruptive
entrants in the healthcare market are pushing for. Their question, getting more
and more urgent by the moment, is: “How do we get what we pay for in healthcare?”
Will we
succeed? Do we really have to adapt ourselves to this radical re-definition? Or
can we count on the basic underpinnings of the market staying mostly the same
for the foreseeable future? Obviously, we can’t know. The shifts above suggest
that the market is moving in a new direction, but that move has not yet reached
a tipping point.
But the real
question to ask is not whether it will happen or not. The right question is: What’s
the smart bet for a payer or provider CFO?
The
smart bet is to act as if this radical re-definition of our value is going to
happen and shift your strategies to account for it.
Here’s the argument for why this will happen:
The shifts in the marketplace, new entrants, and enabling technologies indicate that at least some significant portion of your market is going to be able to find their way to this new value proposition.
The strategies that providers and insurers and new entrants are testing are not mere tweaks, not small programs for particular customers, but systemic changes and strategic shifts across the entire system.
Developing the ability to partner, to know your real costs, to tough-love bargain with suppliers, and to create bundled offerings at the right price will put you in a stronger market position whether the market shifts a little or a lot. Developing new revenue streams and new organizational capabilities never hurts.
Betting that this market shift won’t happen enough to affect you leaves you dependent on the single insured fee-for-service revenue model. You’re like a farmer with a single crop in a market with only a few buyers. Your guess about the future had better be right.
So what are the key strategies for managing this turbulence? We’ll discuss that in Part 4.
Joe Flower has 40 years of experience in the healthcare world and has emerged as a thought leader on the deep forces changing the system in the United States and around the world.
The notion that hospital readmission rates are a “quality” measure reached the status of conventional wisdom by the late 2000s. In their 2007 and 2008 reports to Congress, the Medicare Payment Advisory Commission (MedPAC) recommended that Congress authorize a program that would punish hospitals for “excess readmissions” of Medicare fee-for-service (FFS) enrollees. In 2010, Congress accepted MedPAC’s recommendation and, in Section 3025 of the Affordable Care Act (ACA) (p. 328), ordered the Centers for Medicare and Medicaid Services (CMS) to start the Hospital Readmissions Reduction Program (HRRP). Section 3025 instructed CMS to target heart failure (HF) and other diseases MedPAC listed in their 2007 report. [1] State Medicaid programs and the insurance industry followed suit.
Today, twelve years after MedPAC recommended the HRRP and seven years after CMS implemented it, it is still not clear how hospitals are supposed to reduce the readmissions targeted by the HRRP, which are all unplanned readmissions that follow discharges within 30 days of patients diagnosed with HF and five other conditions. It is not even clear that hospitals have reduced return visits to hospitals within 30 days of discharge. The ten highly respected organizations that participated in CMS’s first “accountable care organization” (ACO) demonstration, the Physician Group Practice (PGP) Demonstration (which ran from 2005 to 2010), were unable to reduce readmissions (see Table 9.3 p. 147 of the final evaluation) The research consistently shows, however, that at some point in the 2000s many hospitals began to cut 30-day readmissions of Medicare FFS patients. But research also suggests that this decline in readmissions was achieved in part by diverting patients to emergency rooms and observation units, and that the rising rate of ER visits and observation stays may be putting sicker patients at risk [2] Responses like this to incentives imposed by regulators, employers, etc. are often called “unintended consequences” and “gaming.”
To determine whether hospitals
are gaming the HRRP, it would help to know, first of all, whether it’s possible
for hospitals to reduce readmissions, as the HRRP defines them, without gaming.
If there are few or no proven methods of reducing readmissions by improving
quality of care (as opposed to gaming), it is reasonable to assume the HRRP has
induced gaming. If, on the other hand, (a) proven interventions exist that reduce
readmissions as the HRRP defines them, and (b) those interventions cost less
than, or no more than, the savings hospitals would reap from the intervention
(in the form of avoided penalties or shared savings), then we should expect much
less gaming. (As long as risk-adjustment of readmission rates remains crude, we
cannot expect gaming to disappear completely even if both conditions are met.)
Numerous analysts assert that the first condition – proven methods to reduce HRRP readmissions exist – has not been met. For example, in an article posted in 2019, the Agency for Healthcare Research and Quality (AHQR) stated “no consensus exists” on how hospitals are supposed to reduce readmissions. But proponents of the HRRP have long asserted just the opposite – that research documenting the existence of numerous proven interventions exists. MedPAC, the nation’s most influential proponent of this claim, made this argument in that 2007 report to Congress that so impressed the authors of the ACA. In Chapter 5 of that report, MedPAC stated, “Research shows that specific hospital-based initiatives to improve communication with beneficiaries and their other caregivers, coordinate care after discharge, and improve the quality of care during the initial admission can avert many readmissions.” (p. 103)
Other individuals and organizations that were influential in the promotion of the HRRP made the same argument. Horowitz and her colleagues at the Yale New Haven Health Services Corporation (hereafter the “Yale group”), who were hired by CMS to develop the HRRP measure of “excess readmissions,” made this argument in their 2011 report to CMS. They claimed “randomized controlled trials” have demonstrated hospitals “can directly reduce readmission rates” and, for that reason, 30-day all-cause readmission rates should be considered a “quality measure.” (p. 8) [3] The mainstream and health policy media have also repeated this claim. For example, a 2011 article posted on Becker’s Hospital Review’s website, which focused on the HRRP, was entitled, “Ten proven ways to reduce hospital readmissions.” A 2018 article in NEJM Catalyst asserts, “[W]hile it may seem that hospitals have little control over what happens once a patient leaves the facility, there are strategies hospitals can deploy to reduce unnecessary bounce-backs….”
An analogy: Off-label
prescribing
It is true that numerous studies exist demonstrating that hospitals can reduce readmissions of carefully selected groups of patients, such as patients who speak English, have phones, live near the hospital, are not demented, and consent to the intervention. With the possible exception of HF patients, however, it is not true that numerous studies exist demonstrating how hospitals are supposed to reduce readmissions as the HRRP defines them. The HRRP defines the pool of applicable patients very broadly. With one exception (patients who leave the hospital against medical advice), the HRRP does not permit hospitals to exclude patients who might be harder or more expensive to work with. And with the exception of planned visits (for surgery or chemotherapy, for example), the HRRP counts all admissions within 30 days after discharge as readmissions even if they are not related to the cause of the original admission. (Although MedPAC recommended, and the ACA required, CMS to punish only readmissions “related” to the condition for which the patient had been previously hospitalized, CMS has, with the exception of the exclusion of planned admissions, ignored that requirement.)
And yet, as I will discuss in
future installments of this three-part series, it was on the basis of a handful
of studies of carefully selected patients that MedPAC, the authors of the ACA,
the Yale group, and others endorsed the notion that hospitals should be
punished for all-cause readmissions for virtually all patients diagnosed
with one of a half-dozen diseases.
To illustrate the inappropriateness of this behavior, it might help to compare it to off-label prescribing of drugs. The AHRQ defines “off-label prescribing” as “when a physician gives you a drug that the US Food and Drug Administration (FDA) has approved to treat a condition different than your condition.” The FDA authorizes the sale of drugs only after the drugs have been shown, by rigorously conducted trials, to work for particular diseases and/or types of patients (for example, adults, not children). Prescribing an FDA-approved drug for a disease or category of patient that was not the subject of the drug company’s research can sometimes lead to useful knowledge about the drug, but it can also create adverse outcomes. Because of the risk of adverse outcomes, drug companies are not allowed to promote a drug for off-label purposes.
In the remainder of this
article, I will discuss three examples of studies which demonstrated methods of
reducing readmissions for a carefully selected pool of patients, but
which did not demonstrate that the interventions could reduce readmissions for
the much more broadly defined pool of patients to which the HRRP applies. As
you read these examples, and other examples in later installments in this
series, please ask yourself this question: “If drug companies are not allowed
to promote drugs for purposes for which the drugs have not been tested, why do
we tolerate the promotion of health policies for purposes for which they have
not been tested?”
Three illustrations of the “off
label” problem
As I noted above, the AHRQ stated in a 2019 article that “no consensus exists” on how hospitals are supposed to reduce readmissions. The agency then cited two “notable” studies that reported on interventions that reduced readmissions: The Care Transitions Intervention developed by Coleman et al., and the Project RED trial conducted by Jack et al. Both of these studies are frequently cited by proponents of the HRRP and in literature reviews. The AHRQ later cited a Danish study conducted by Ravn-Neilsen et al. which also reported on an intervention that reduced readmissions.
The authors of all three of
these studies imposed severe limits on the patients who could participate,
limits hospitals are not allowed to impose under the HRRP.
The study by Coleman et al. (which was also cited by MedPAC and the Yale group) employed the following exclusion criteria: The participants had to be over 65, be admitted for a non-psychiatric condition, could not be in a nursing home, could not be enrolled in another research study, had to live “in a pre-defined geographic radius of the hospital” to make a home visit “feasible”, “have a working telephone,” “be English-speaking,” “show no documentation of dementia,” not be discharged to a hospice, and provide consent. These requirements led to the exclusion of 1,146 patients out of the initially screened 1,905 patients who were diagnosed with one of the eleven diseases that were the subject of the study. Here is how those 1,146 patients – 60 percent of those screened – were excluded:
Jack et. al. applied equally severe limitations. According to the methods section of their article: “Patients had to [be over 18 and] have a telephone, be able to comprehend study details and the consent process in English, and have plans to be discharged to a US community. We did not enroll patients if they were admitted from a skilled nursing facility or other hospital, transferred to a different hospital service before enrollment, admitted for a planned hospitalization, were on hospital precautions or suicide watch, or were deaf or blind.”
Ravn-Neilsen et al. also imposed substantial limitations on
their participants: Patients had to be over 18, speak Danish, receive five or
more drugs on a daily basis, not be terminally ill, suicidal, in custody, nor
“under isolation precautions, or have aphasia or severe dementia.”
Implications
According to the AHQR, the Coleman, Jack, and Ravn-Neilsen
studies are high-quality studies that demonstrate that hospitals can reduce
readmissions. Here is how the AHQR described the Coleman and Jack studies: “These
studies … successfully reduced readmissions and emergency department visits
after discharge.” That statement is literally true. But it is extremely
misleading to assert or imply that these studies are examples of how hospitals
can reduce readmissions under the HRRP. Hospitals to which the HRRP applies are
not allowed to pick and choose their patients as the investigators in the
Coleman, Jack and Ravn-Neilsen trials did. It would have taken just a single
sentence for the AHQR to state that fact.
My purpose in pointing out the dearth, possibly the complete
absence, of research showing hospitals how to reduce HRRP-defined readmissions
is not to suggest that hospitals are not trying to reduce readmissions. The
evidence indicates they are trying, and many are spending lots of money in the
process. My purpose, rather, is to document an explanation for why some,
perhaps many, hospitals might feel compelled to game the HRRP.
Nor is it my purpose to suggest that there is nothing society
can do to reduce readmissions. The three studies I discussed above prove there
is much that can be done to reduce readmissions. I do mean to suggest the HRRP
is very poorly designed to achieve that end.
In Parts 2 and 3 of this series I will review the studies
used by MedPAC and the Yale group to justify their support for the program. We
will see that the evidence they relied on to justify their support was woefully
insufficient.
[1]
Section
3025’s description of the seven conditions endorsed by MedPAC’s 2007 report is
somewhat cryptic. It reads: “Beginning with fiscal year 2015, the Secretary
shall, to the extent practicable, expand the applicable conditions beyond the 3
conditions for which measures have been endorsed as described in subparagraph
(A)(ii)(I) as of the date of the enactment of this subsection to the additional
4 conditions that have been identified by the Medicare Payment Advisory
Commission in its report to Congress in June 2007 and to other conditions and
procedures as determined appropriate by the Secretary.” The reference to three
previously “endorsed” conditions apparently refers to heart failure, AMI, and
pneumonia, readmission conditions CMS adopted in 2009 for its Hospital Compare
report. Section 3025 also left
it up to the Secretary to determine the length of time after discharge – 30
days, 60 days, etc. – within which readmissions will be measured.
[2] Although readmissions within 30 days have declined somewhat over the last decade for both Medicare enrollees and the privately insured, visits to hospital emergency rooms and observation stays have risen rapidly. Figure 1-8 of MedPAC’s June 2018 Report to Congressshows unplanned readmissions of Medicare FFS enrollees fell by 19 percent between 2008 and 2016 while ER use rose 33 percent and observation stays rose 71 percent. Sabbatini and Wright found that 30-day readmission rates as traditionally defined fell 19 percent among the privately insured between 2007 and 2015, but readmission rates fell only 1 percent over that period if (a) we count observation stays as an admission and (b) we count return visits within 30 days after discharge from an observation stay as a readmission. Wadhera et al. reported that 30-day
readmissions among Medicare FFS enrollees as traditionally defined fell between
2012 and 2015, but that readmissions following ER visits and observations stays
rose faster than readmissions fell, and the net result was an increase in total
30-day “revisits.” By my calculation, one-third of the “revisits” reported by
Wadhera et al. were revisits after ER visits and observations stays.
Studies suggesting that the HRRP has increased mortality among heart failure patients also constitute evidence suggesting gaming.
[3] Here is a longer version of
the Yale group’s declaration that research has clearly characterized methods by
which hospitals can reduce readmission rates:
Furthermore, randomized controlled trials have shown that improvement in the following areas can directly reduce readmission rates: quality of care during the initial admission; improvement in communication with patients, their caregivers and their clinicians; patient education; pre-discharge assessment; and coordination of care after discharge. [Sixteen endnotes followed.] Evidence that hospitals have been able to reduce readmission rates through these quality of-care initiatives illustrates the degree to which hospital practices can affect readmission rates…. Given that studies have shown readmissions within 30-days to be related to quality of care, and that interventions have been able to reduce 30-day readmission rates, it is reasonable to consider an all-condition 30-day readmission rate as a quality measure. [p. 8]
[4] Although MedPAC laid out
their rationale for the HRRP in their 2007 report, they did not formally
recommend the HRRP to Congress in that report. They did that in their June 2008
report.
Kip Sullivan is a member of the advisory board of
Health Care for All Minnesota, and a member of the Minnesota chapter of
Physicians for a National Health Program.